
Mastering XPath for Complex Data Extraction and Web Scraping
In data extraction and web development, precision is crucial. To guarantee the ongoing delivery of flawless applications that offer clients outstanding experiences, navigating the challenging landscape of web automation testing is essential.
However, achieving this goal can provide serious difficulties. Finding site elements for interaction with accuracy and efficiency is a recurring challenge on this trip. As a solution, Selenium WebDriver appears, providing a variety of tools and locators such as XPath, CSS Selector, and more, helping businesses navigate XML elements.
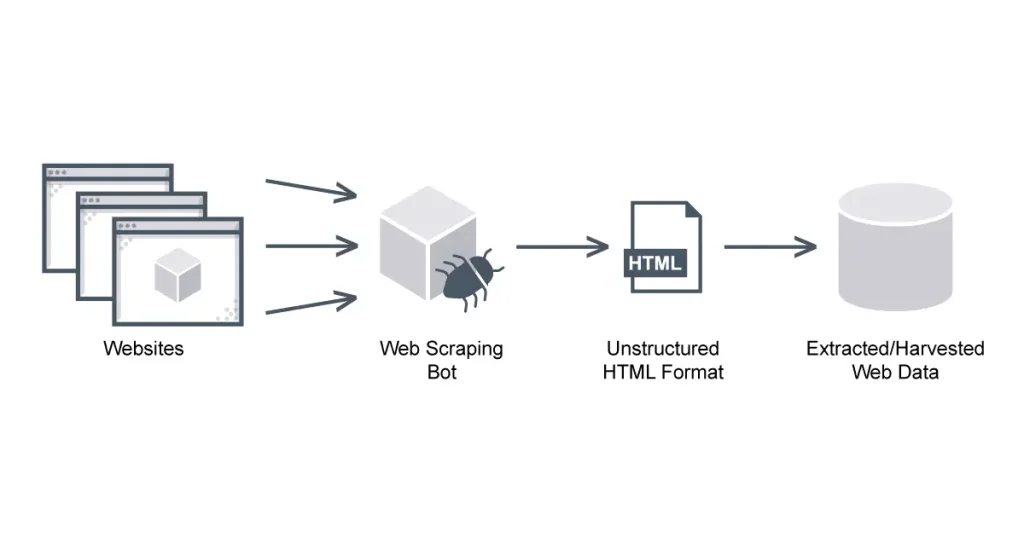
The task of web scraping calls for a wide range of abilities. Obtaining the HTML from the website you are scraping is the first step. After that, you must figure out how to parse it and get the data you need.
Web Scraping
Web scraping is the automated procedure used to retrieve data from websites. Obtaining material for a website is involved. Next, you parse it to identify data points. You then extract that data for use at a later time. Custom website data extraction solutions are used by organizations and researchers for a variety of objectives. These include of creating machine learning datasets, tracking prices, and conducting market research.
The goal of web scraping is not data theft. It involves converting unprocessed data into insightful knowledge. Additionally, you can monitor rival pricing tactics. Using web scraping, you can obtain important data in bulk.
Types of Web Scraping
Conventional Data Scraping
Conventional data scraping doesn’t always require an internet connection or browsing websites to gather information. Instead, it entails the extraction of data from numerous offline, organized sources, including:
- Relational (SQL) and non-relational (NoSQL, such as MongoDB) databases are included in this category.
- Spreadsheets: CSV files and Excel files are common formats.
- Reports and Visual Aids: These include email reports, HTML reports, and graphical aids such as pie charts and bar charts.
- Usually, the information gathered from these sources is combined to create a consolidated repository of instructive documents that may be examined or applied in many ways.
Scraping with a Browser
In browser-based scraping, websites are navigated and data is extracted using a web browser. This approach can be carried out manually or with the use of automated technologies, and it requires an active internet connection. Usually, the procedure entails:
Launching or Accessing a Website:
Using a web browser such as Firefox, Chrome, or Safari, visit the intended website.
Data extraction methods include copying information by hand and utilizing automated programs like Selenium to scrape the needed data from the website.
The Typical Process for Web Scraping Determines the Website to Be Scraped:
- Choose the website to extract data.
- Make sure you have the required authorizations and that your scraping operations adhere to the terms of service of the website as well as any applicable laws.
Select the Right Tools:
Select online scraping technologies based on the particular requirements of your project. These could be browser automation technologies (like Selenium), programming languages (like Python), or libraries (like BeautifulSoup, Scrapy, or Puppeteer).
Develop the Scraping Code:
Write your web scraping script using the chosen tools and programming language. Use techniques like HTML parsing, form submissions, button clicks, or page navigation to access and extract the targeted data.
Manage Captchas and Authentication:
Some websites use security measures like Captchas or require user authentication to prevent scraping. Implement strategies to handle these challenges, such as using a captcha-solving service or providing login credentials in your script.
Execute Data Extraction:
Apply parsing methods, regular expressions, or specialized library functions to format the data as needed.
Manage Pagination and Iteration:
If the website spans multiple pages or requires iterative actions to access all desired data, implement techniques to handle pagination. This could involve iterating through URLs or interacting with “Next” buttons to retrieve data from each page.
The Needs and Uses of XPath in Web Scraping
XPath is an essential component of web scraping that allows the identification of particular components of an HTML document to scrape. This is because frequent changes and complex web pages require the use of well-developed or the best standards when developing XPaths for web scraping.
What is XPath?
XML and HTML are very much different because XML is more or less general while HTML is highly specific and practical; that is why XPath is necessary especially when it comes to working with HTML because HTML has a different hierarchy than XML.
The Importance of XPath in Web Programming
In web development, XPath, or XML Path Language, is an essential tool for finding items within the XML structure of web publications.
It is useful not only for XML navigation but also for navigating HTML documents, which are the foundation of the internet. Developers and testers want precise ways to interact with features within these documents due to the widespread use of online apps.
This accuracy is made possible with XPath, which lets you pick particular items regardless of where they are in the document structure. This is particularly helpful for dynamic websites where elements may lack distinct names or fixed locations.
Document Object Model (DOM)
DOM has been mentioned as one of the crucial elements of web design. Knowledge of the document object model or simply DOM is deemed innate for writing XPaths. DOM is a programming interface for HTML and XML documents and renders the document in the form of an object tree. Each object, or node, corresponds to a part of the document (like an element, attribute, or text).
In the DOM, nodes have hierarchical relationships: this means that a node can be a child node of another node and vice-versa a node can have a node that contains it.
Xpaths for complex data extraction and web scraping
Using the text() Function
The text() function lets you select elements based on their inner text. This is particularly useful when the element’s name or attributes are not unique.
For more flexible text matching, you can combine text() with the contains, starts-with, or ends-with functions to match elements based on partial text content.
Choosing Components by Name
Start by inspecting the HTML structure of the page you want to scrape using the “Inspect Element” function of your browser. This will make it easier for you to write accurate XPaths by helping you grasp the hierarchy and nesting of elements.
Targeting particular sections of an HTML text can be done quickly and easily by using basic XPaths to pick elements by name. Particularly for novices or when working with basic HTML structures, this is helpful.
Employing Operators, AND and OR
You can combine several qualifiers to produce more exact and adaptable selects using XPath’s AND and OR operators.
- The AND operator chooses items that satisfy all of the given criteria.
- The OR operator chooses items that satisfy at least one of the given requirements.
Making use of the includes Function
XPath’s includes function lets you choose elements based on whether a substring appears in the value of an attribute. When managing dynamic attribute values or in situations, where you are unsure of the precise attribute value, this is helpful.
Using starts-with and ends-with Functions
- starts-with Function: Selects elements with attribute values that start with a specific string.
- ends-with Function: Picks elements whose attribute values finish in a particular string.
These functions are useful for dealing with dynamic or variable attribute values.
Using following and preceding Axes
This is useful for selecting elements that are related to the current element but not directly nested within it.
- following Axis: Selects all elements that follow the current element.
- preceding Axis: Selects all elements that precede the current element.
Using ancestor, descendant, and parent Axes
These axes allow you to navigate the HTML hierarchy to select elements based on their relationship to the current element.
- ancestor Axis: Selects all ancestor elements of the current element.
- descendant Axis: Picks every element that is the current element’s descendent.
- parent Axis: Selects the parent element of the current element.
Testing XPaths
Always test your XPath expressions in the browser console or using tools like XPath Helper to ensure they correctly select the desired elements.
Qualities of an Effective Xpath Expression
XPath is a vital tool for web scraping because it enables you to pick the precise items you want without picking any other elements. This is particularly crucial when using scrapers on websites that have dynamic data since different items being scraped may have different or different page structures.
A good XPath expression should be resilient enough to accommodate page structural changes but specialized enough to capture only the information you need. It should also be able to adapt to differences in the page layout between the various objects that are being scraped.
Moreover, XPath expressions are crucial for online testing, especially when used in conjunction with AI-driven platforms like LambdaTest for test orchestration and execution. A cloud-based platform like LambdaTest makes cross-browser compatibility testing easier for developers and testers across 3000 operations systems and browser versions
Role of test scenario in Xpath
When evaluating the accuracy, effectiveness, and dependability of XPath expressions used to query XML documents, a test scenario in XPath is essential.
Validation of XPath Expressions:
- Ensures that the XPath expressions accurately navigate and select the intended elements or attributes from the XML document.
Functionality Testing:
Tests the functionality of the application or system that relies on XPath for data extraction, ensuring it behaves as expected when processing XML data.
Error Handling:
Identifies potential errors or issues in XPath expressions, such as syntax errors, incorrect paths, or invalid queries, and helps rectify them before deployment.

Best Practices for Advanced XPath Usage
Thoroughly Validate Locators
Before integrating XPath expressions into your test scripts, ensure their effectiveness by conducting thorough testing and validation. This step is crucial to confirm that the XPath expressions accurately locate the intended elements across different browsers and environments.
Utilize Browser Developer Tools
Make use of browser developer tools like Chrome DevTools or Firefox Developer Tools to examine and test XPath expressions directly within the browser. These tools can help refine your XPath expressions and troubleshoot any locator-related issues effectively.
Prefer Relative XPath
Whenever possible, prioritize relative XPath expressions that rely on the context of the element rather than absolute paths. Relative XPaths are more resilient to changes in the HTML structure, enhancing the maintainability of your scripts.
Handle Dynamic Content Appropriately
When dealing with dynamic content or elements with changing attributes, use dynamic XPath techniques such as contains() or starts-with(). These methods create robust and adaptable locators that can accommodate changes in the web page’s layout or content.
Conclusion
Xpath Queries is an effective web scraping tool that lets you quickly traverse and pick out particular parts of a webpage. It’s crucial to understand the fundamental syntax and features of Xpaths, but there are a few best practices and pointers to remember while utilizing them for web scraping.
It is often a good idea to make it easy to navigate and choose particular items from a webpage. To make sure you’re picking the components you want, it’s best to test your Xpath Queries on a subset of the homepage before running them across the whole thing. Using relative Xpaths is also a good idea because they are less likely to break if the webpage’s structure changes.
FURTHER READING
- Data-Driven Decision-Making in Modern Businesses
- How Can Businesses Successfully Navigate Digital Transformation?





